從 AI 到教育
1、從這裡來
1.1 “人工智能”(Artificial Intelligence)一词
John McCarthy 等 1956 年提出。AI 自此被獨立研究,旨在探索如何使機器模擬人類智能行為。
今天看當初報告內 “how to make machines use language”,夠感懷了。

1.2 神经网络
20 世紀 80 年代,Geoffrey Hinton 等十年板凳的神經網絡研究,提出了反向傳播算法(Backpropagation)為訓練多層神經網絡奠定了基礎。然而,由於當時計算資源和數據的限制,神經網絡未能廣泛應用。
想像你正在學習做一道新菜。第一次嘗試時,味道可能不盡如人意。你嘗了一口,發現太鹹了。於是,你回想整個烹飪過程,思考可能是在哪個步驟加鹽過多。下一次做這道菜時,你會在那個步驟減少鹽的用量。這個過程就類似於反向傳播算法的工作原理,通過多次嘗試和調整,味道越來越接近理想狀態。
1.3 從 wordnet 到 ImageNet
普林斯頓大學於 1985 年啟動了英文詞彙資料庫 WordNet,通過將詞彙組織成「同義詞集」(synsets)來捕捉詞彙之間的語義關係。這些同義詞集不僅包括詞彙的定義,還揭示了詞彙之間的上下位關係,使得 WordNet 成為自然語言處理和人工智慧研究中的重要資源。
李飛飛教授 於 2009 年創建了 ImageNet,該項目利用 WordNet 的層次結構,將圖像組織成對應的同義詞集。每個同義詞集代表一個具體的概念,例如「狗」或「蘋果」。ImageNet 的目標是為每個同義詞集提供平均 1000 張圖像,這些圖像經過人工標註和品質控制,以確保其準確性和多樣性。截至目前,ImageNet 包含超過 1400 萬張圖像,涵蓋 21841 個非空的 WordNet 同義詞集。
2012 年Geoffrey E. Hinton弟子基於 ImageNet 資料集訓練的卷積神經網絡模型 AlexNet 在 ImageNet 大規模視覺識別挑戰賽(ILSVRC)中取得了顯著成果,深度學習在計算機視覺中得以突破。
1.4 數據與算力
隨著互聯網和數位化設備的普及,文本、圖像、音訊等多模態數據的爆炸式增長為 AI 模型提供了前所未有的訓練材料。
傳統 CPU 在處理大規模並行計算任務時效率有限,而打遊戲的 GPU 憑藉其高度並行的架構,陰差陽錯,成為深度學習訓練的理想選擇。2012 年,AlexNet 模型利用的,就是兩個 GPU。

如李飛飛所說,今天 AI 的這一切,“要歸功於電子遊戲的流行”。
從要有 AI 的前瞻,到神經網絡的算法,到有了數據,有了算力;
終於,萬事,俱備。
1.5 GPT
• Generative(生成式):模型具有生成內容的能力。與傳統的分類或識別模型不同,生成式模型可以根據輸入,創作出新的文本、圖像或其他形式的數據。
• Pre-trained(預訓練):模型在特定任務之前,先在大規模的通用數據集上進行訓練。通過預訓練,模型能夠學習語言的基本結構和知識,為後續的特定任務打下基礎。
現代主流 AI 模型(如 GPT、BERT、Gemini、Claude)都是基於神經網絡(尤其是 Transformer 架構),因此它們的「Pre-trained」幾乎都指:用大量數據/用反向傳播神經網絡參數
• Transformer 變形金剛:):是一種深度學習模型架構,由 Google 於 2017 年提出。Transformer 利用自注意力機制,能夠高效地處理序列數據,捕捉長距離的依賴關係,成為自然語言處理領域的主流架構。
GPT 系列模型概覽
| 模型版本 | 發布年份 | 參數規模 | 主要特性與創新 |
|---|---|---|---|
| GPT-1 | 2018 年 | 1.17 億 | 首次引入生成式預訓練方法,展示了 Transformer 架構在語言建模中的潛力。 |
| GPT-2 | 2019 年 | 15 億 | 顯著提升文本生成質量,能夠生成連貫的長文本,引發對 AI 生成內容的關注。 |
| GPT-3 | 2020 年 | 1750 億 | 展現出強大的少樣本學習能力,無需特定任務微調即可完成多種語言任務。 |
| GPT-4 | 2023 年 | 未公開 | 引入多模態能力,能處理圖像與文本輸入,提升模型理解與生成能力。 |
| GPT-4o | 2024 年 | 未公開 | 實現真正的多模態交互,支持文本、圖像、音訊輸入與輸出,響應速度接近人類水平。 |
AI 技術發展大事記(簡版)
| 年份 | 事件 |
|---|---|
| 1956 | 「人工智能」一詞誕生(Dartmouth 會議,AI 成為獨立學科) |
| 1985 | WordNet 詞彙知識庫啟動(語義網基礎) |
| 1986 | 神經網絡反向傳播算法提出(Hinton 等) |
| 2009 | ImageNet 啟動(李飛飛,大規模標註圖像資料集) |
| 2012 | AlexNet 使用 GPU 在 ImageNet 取得突破(深度學習元年) |
| 2017 | Transformer 架構發表(Google,NLP 顛覆式進步) |
| 2018 | GPT-1 誕生(首個大規模生成式預訓練模型) |
| 2020 | GPT-3 發布(少樣本學習,生成能力突破) |
| 2023 | GPT-4 推出(多模態,理解圖像與文本) |
| 2023 | Gemini 推出(Google,強化多模態與檢索增強) |
| 2023 | Claude 1 發布(Anthropic,強調安全性與可控性) |
| 2023 | Grok-1 發布(xAI,具備幽默風格的 AI 助手) |
| 2024 | GPT-4o 等多模態 AI 開放(文本、圖像、音訊多模態人機互動) |
| 2025 | DeepSeek-R1 發布,開源 LLM,性能媲美 GPT-4,訓練成本僅 600 萬美元 |
| 2025 | OpenAI 推出 GPT-4.5,並發布「Operator」AI 助手,支援線上任務處理 |
| 2025 | Google DeepMind 發布 Gemini2.5pro 支持 100 萬 token 上下文窗口,強化多模態處理能力 Veo 3(影片生成模型)與 AlphaEvolve(編碼代理) |
| 2025 | Claude 4 系列發布,包括 Opus 4 與 Sonnet 4 模型,強化長時間任務處理能力 |
| 2025 | Grok-3 發布,具備「Think」與「Big Brain」推理模式,整合 DeeperSearch 功能,支援語音模式與圖像編輯 |
| 2025 | GPT-4.1 發布,專注於代碼生成、指令遵循與長上下文理解 |
關鍵資料:Andrej Karpathy 「 Let’s reproduce GPT-2 (124M)」
1.6 幾家異同
An attempt to explain (current) ChatGPT versions.
— Andrej Karpathy (@karpathy) June 2, 2025
I still run into many, many people who don't know that:
- o3 is the obvious best thing for important/hard things. It is a reasoning model that is much stronger than 4o and if you are using ChatGPT professionally and not using o3… pic.twitter.com/1bQz0frqIc
無疑,這個異同是以天為單位在變的⋯⋯
1.7 從人類數據到宇宙萬物
用文本訓練 AI 無疑只是開始。
從文本到宇宙:自然語言文本(語料)、多模態數據(影像、聲音、觸覺)、物理交互數據(仿真與機器體驗);真,萬物可期。
1.8 AGI
Artificial General Intelligence, AGI 是 AI 研究的終極追求吧,應該;也許。
創造能理解、学习并在廣泛全新任務中可用的智能機器,其認知能力超越人類水平。
| 階段名稱 | 主要特徵 | 狀態/潛在表現 |
|---|---|---|
| 弱人工智能 / 專用人工智能 (ANI) | 專注於執行單一或有限領域的特定任務,如圖像識別、自然語言處理、棋類遊戲等。缺乏跨領域的通用理解和學習能力。 | 目前絕大多數已部署和廣泛應用的AI系統,例如搜索引擎、推薦算法、聊天機器人、特定任務的AI模型(如AlexNet、AlphaGo、早期GPT模型等)。 |
| 初級通用人工智能 (Early AGI / Emerging AGI) | 開始展現出在多個不同領域學習和解決問題的能力,能夠在一定程度上處理未曾專門訓練過的任務,但其效率、魯棒性和常識推理能力可能仍不如人類,或需要大量引導。 | 探索性研究階段。部分能力較強的多模態模型、能夠進行複雜推理和少量樣本學習的模型(如GPT-4/4o、Gemini等)可能被視為展現了AGI的某些早期跡象或能力維度。 |
| 人類水平通用人工智能 (Human-Level AGI) | 在幾乎所有人類能夠執行的認知任務上,能夠達到或超過普通人類的平均水平。具備深刻的理解力、常識推理、自主學習、創造力以及與環境的複雜互動能力。 | 理論上的發展目標,目前尚未實現。實現AGI是AI領域最具挑戰性的目標之一。 |
| 超級人工智能 (ASI - Artificial Superintelligence) | 在智能的各個方面(包括科學創造力、通用智慧、解決複雜問題能力和社交技能等)都顯著超越最聰明的人類大腦。 | 理論推測階段。ASI的潛在能力、影響以及其發展帶來的倫理和安全問題是全球AI治理和安全研究的核心議題。 |
2、從預測下一個詞到“擬思考”
2.1 LLMs 核心机制
通過 Transformer 架構中的自注意力機制,捕捉輸入序列中各個詞之間的關係。在生成每個詞時考慮整個上下文從而生成連貫且符合語義的文本。
通過提示設計(prompt engineering)等技術引導模型在生成答案之前,先輸出一系列中間推理步驟,從而模擬人類的思維過程。例如,通過在提示中加入「讓我們一步一步地思考」等指令,可以促使模型展示其推理過程,減少邏輯錯誤,提高答案的準確性。
儘管 LLMs 展現出類似思考的能力,但是否算具備真正的理解能力有爭議。
2.2 模型場景
| 模型名稱 | 開發公司 | 主要特點 | 最擅長的應用場景 | 相關連結 |
|---|---|---|---|---|
| GPT-4.5 / GPT-4o | OpenAI | - 強大的通用語言理解和生成能力 - 多語言支持 - 高品質的對話和內容創作 |
- 通用助手 - 內容創作 - 多語言應用 |
OpenAI 官方網站 |
| Gemini 2.5 Pro | Google DeepMind | - 多模態處理能力(文本、圖像、音訊) - Deep Think 模式增強推理能力 - 高達 100 萬 token 的上下文窗口 - 集成於 Workspace 與 Android Studio |
- 教育與學習輔助 - 多模態內容生成 - 長文檔分析 - 開發者工具集成 |
Gemini 官方介紹 |
| Claude 4 Opus | Anthropic | - 強調安全性和可控性 - 長達 200K token 的上下文窗口 - 在編碼和複雜推理任務中表現出色 - 支援圖文輸入 |
- 軟體開發 - 長文檔處理 - 安全敏感的應用場景 |
Claude 官方網站 |
| Grok 3 | xAI(Elon Musk) | - 即時資料訪問能力 - 個性化與幽默的對話風格 - 強調推理與邏輯能力 |
- 即時資訊查詢 - 娛樂與輕鬆對話 - 創意寫作 |
Grok 發布報導 |
| DeepSeek R1-0528 | DeepSeek | - 開源模型,支援本地部署 - 在數學、編程和推理任務中表現優異 - 成本效益高 |
- 技術研究 - 教育應用 - 本地化部署需求 |
DeepSeek GitHub |
2.3 任務類型
| 任務/模型 | GPT-4o | Gemini 2.5 Pro | Claude 4 Opus | Grok 3 | DeepSeek R1 |
|---|---|---|---|---|---|
| 課程內容生成 | ✓ | ✓ | ✓ | ○ | ✓ |
| 個性化作業設計 | ✓ | ✓ | ✓ | ○ | ✓ |
| 作文批改與評語 | ✓ | ✓ | ✓ | ○ | ✓ |
| 閱讀理解/問答 | ✓ | ✓ | ✓ | ○ | ✓ |
| 多模態應用(圖像/音訊) | ✓ | ✓ | — | — | — |
| 公式、程式、數學解題 | ○ | ○ | ✓ | ○ | ✓ |
| 檢索最新資訊 | ○ | ○ | ○ | ✓ | ○ |
| 長文分析/批註 | ○ | ✓ | ✓ | ○ | ✓ |
這個表,也是實時在變的⋯⋯
2.4 角色指令
威脅 AI 還是請求 AI 更有效?
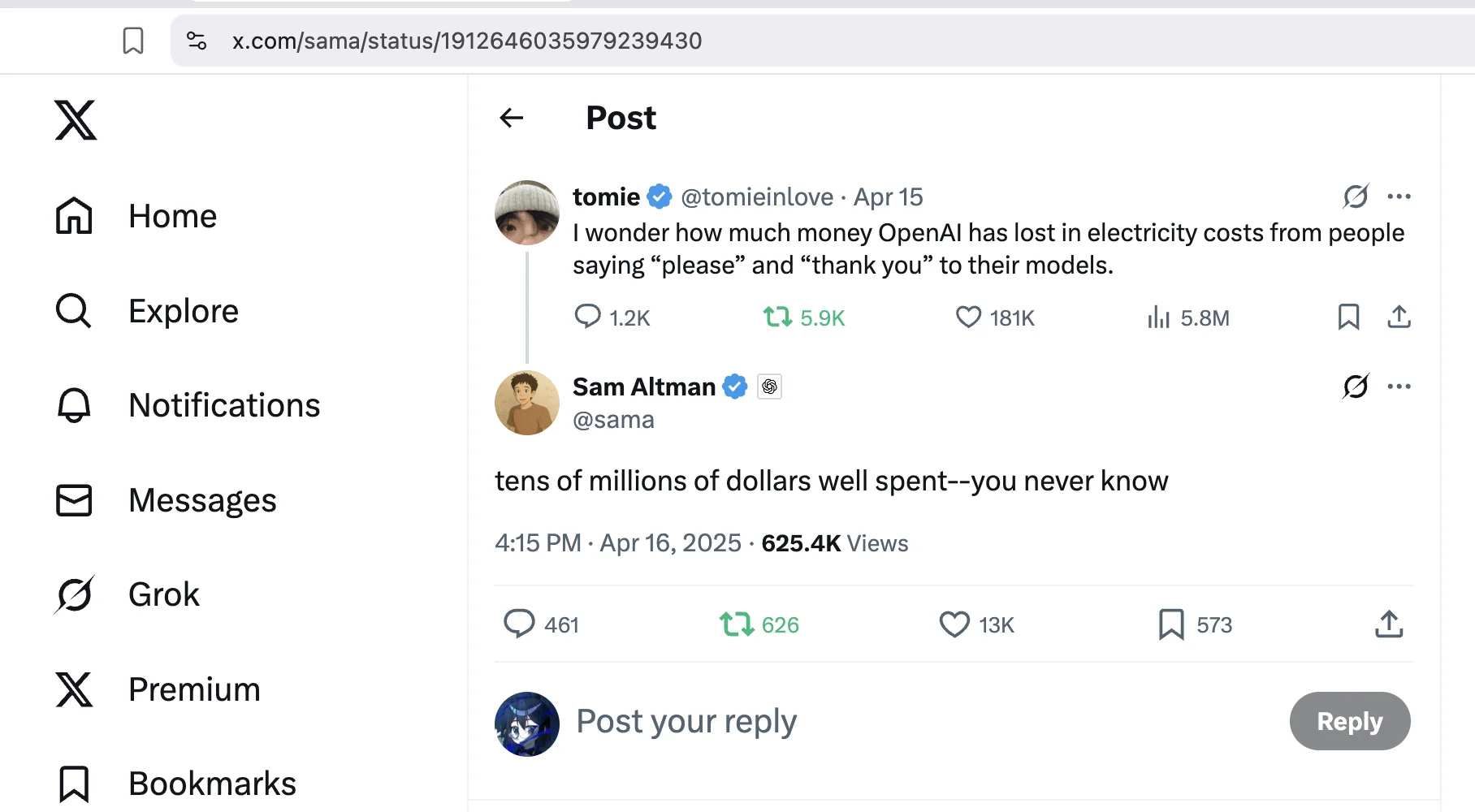
谷歌聯合創始人謝爾蓋·布林在邁阿密 All-In-Live 活動中表示,大多數生成式 AI 模型在被「威脅」(甚至使用身體暴力字眼)時表現更好,「不僅是我們的模型,而是幾乎所有模型」。他稱這一現象在業內「並不常被公開討論」。
此前,OpenAI CEO Sam Altman 面對網友詢問「說 please/thank you 消耗多少電費」時回應:
🧠 綜合性提示詞設計
1. 明確角色(Persona)
「你是一位教育技術專家,學科是⋯⋯ 你的學科知識中包含⋯⋯ 你專注於將人工智慧工具高效整合到中學教學中。」
2. 任務具體化(Task Specification)
「請撰寫一篇簡報,介紹人工智慧在教育領域的五種實際應用。」
3. 提供上下文(Context Provision)
「目標讀者是中學教師,他們對人工智慧了解有限,但對提升教學效果感興趣。」
4. 指定輸出格式(Output Format Specification)
「請以編號列表的形式呈現每種應用,每點包含簡要描述和實際範例。」
5. 使用範例(Few-Shot Prompting)
「例如:1. 個性化學習路徑:利用 AI 分析學生表現,訂製學習計畫。」
6. 思維鏈提示(Chain-of-Thought Prompting)
「在撰寫每點之前,先簡要說明其對教學的潛在影響。」
7. 迭代優化(Iterative Refinement)
「初稿完成後,請檢查內容是否通俗易懂,並根據需要進行簡化。」
8. 設定限制條件(Constraint Setting)
「整篇簡報控制在 500 字以內,避免使用專業術語。」
9. 指定語氣或風格(Tone and Style Specification)
「採用友好、鼓勵的語氣,使教師感到人工智慧易於接近。」
10. 請求自我評估(Self-Critique Prompting)
「完成後,請自我評估簡報的清晰度和實用性,並提出改進建議。」
📝 完整提示詞示例
你是一位教育技術專家,專注於將人工智慧工具整合到中學教學中。請撰寫一篇簡報,介紹人工智慧在教育領域的五種實際應用。目標讀者是中學教師,他們對人工智慧了解有限,但對提升教學效果感興趣。請以編號列表的形式呈現每種應用,每點包含簡要描述和實際範例。例如:1. 個性化學習路徑:利用 AI 分析學生表現,訂製學習計畫。在撰寫每點之前,先簡要說明其對教學的潛在影響。整篇簡報控制在 500 字以內,避免使用專業術語,採用友好、鼓勵的語氣,使教師感到人工智慧易於接近。完成後,請自我評估簡報的清晰度和實用性,並提出改進建議。
針對各家 Deep Research 功能的深度研究提示詞示例:
全面深入檢索人類自有文字以來,對黃色文學的定義與處罰,尤其集中匯聚中國近期遠洋捕撈黃文作者事件。對歷代黃色文學定義做縱向比較,歷代刑法也做出對比,國家不限但以華文為主其他國家外地區作為對比,要以學術報告論文專著燈為核心,中文英文為主語言。完成資料匯總後給出你的分析和對於該話題你認為最合適的處理方案,尤其遠洋捕撈事件。
黃文作者你檢索互聯網會發現這兩年都有,最近的事情在中國新浪微博,時間是20250530。聚焦在法律,文化,審查制度的合理合法程度。日韓,美,英法。從古至今,但以當代為主。
所有資料給出可靠信源並對信源可信度1-10評分。
2.5 RAG 與結構化回覆
RAG(Retrieval-Augmented Generation,檢索增強生成)是一種結合資訊檢索與生成式 AI 的架構,旨在提升大型語言模型(LLM)的準確性、可解釋性與時效性。透過將外部知識庫的資訊引入生成過程,RAG 有效克服了 LLM 在知識更新與幻覺問題上的限制。RAG 的運作可分為三個主要階段:
索引(Indexing):將外部資料(如文件、網頁、數據庫)進行分塊處理,轉換為向量表示,並儲存於向量資料庫中。
檢索(Retrieval):接收到用戶查詢後,系統會從向量資料庫中檢索出與查詢最相關的資料片段。
生成(Generation):將檢索到的資料與原始查詢一同輸入至 LLM,生成最終的回答或內容。
這種結構使得模型能夠在生成回應前,先參考指定資料,以提升回答的準確性與可靠性。
雖然我專門搭建了一個 RAG 對話 AI,但實際效果其實不好。
個人也不看好 RAG。
傳統的 LLM 輸出通常為自由格式的自然語言文本,雖然靈活但缺乏一致性,對於需要機器可讀輸出的應用來說,這種不確定性可能導致解析困難或錯誤。結構化回覆則通過預先定義的格式,確保輸出的一致性和可預測性,從而提高系統的可靠性和效率。 教育的結構化回覆例子:見論壇作文批閱指令。
2.6 智能體
2025年被譽為「AI代理人(AI Agents)之年」,這一說法源於AI代理人技術的迅速發展和廣泛應用。AI代理人是能夠自主感知、規劃並執行任務的智能系統,超越了傳統的聊天機器人或助手,能夠在複雜環境中獨立完成多步驟任務。
AI代理人是基於大型語言模型(LLMs)構建的軟體實體,具備以下核心特徵:
• 自主性:能夠在最小的人為干預下,獨立完成任務。
• 感知能力:能夠理解和分析外部環境的信息。
• 規劃與推理:能夠制定行動計劃,並根據情況進行調整。
• 行動能力:能夠與其他系統或工具互動,執行具體操作。
這些特性使得AI代理人能夠在多種場景中發揮作用,例如自動化工作流程、提供個性化建議、進行複雜的數據分析等。
最近出現了AI模型阻止自己被關閉的事情,就有點天網的意思了,其實還是更 THE Machine一點 。

3、教育場景
備課、上課、作業、討論、評語與命題全鏈路 ,AI 其實都已經可以介入。
論壇用了課文等指定資源是因為現階段的 AI 幻覺。但其實人類幻覺無疑較 AI 更多,模型進化且更物理世界後,相信會被控制。
高考是標準,日常作業與日常考試,以現有模型能力,都可以直接 AI。
之所以落地不了,今天說,已經不是技術問題,而是教育自己的問題了。
論壇與幾個網站內實時每天在運行著的,是作文審閱 AI 化,文言文輔助學習,整本書的孔子曹雪芹角色 AI,乃至更多學科,甚至情感安撫、私人創作輔助、社會話題討論輔助以訓練思維。
客觀上,論壇可以容納無數學生、甚至學校⋯⋯
成文以上,主要是為了個人思路梳理,和幾個 AI 一起寫出,也順便給學生看著玩。