AI 閱卷報告
語文試卷中一道主觀題,手寫,4-5行,每行約20字,701份,高質量審閱評分,一個教師,高強度的話大概要多少個小時完成?
AI 審閱+人類審核呢?
701 份,每份識別+思考約 40 秒左右,輸出 1 秒。
這是我實測下來的觀察數據。
選擇模型:Gemini 2.5 Pro Preview 03-25,以 Requests per minute (RPM) 現在最低值 150 計算的話,利用滿 150 RPM 的速率並行發送請求,完成 701 份試卷大約需要 5 分 21.4 秒。
同步處理(即發送一個請求,等待 41 秒完成,再發送下一個)的話, 701 份 * 41 秒/份 = 28741 秒 ≈ 479 分鐘 ≈ 8 小時。
正常調用 API 自然會設計成並行。
沒錯,一個老師辛苦折騰20多個小時,其實就是 AI 的 5 分 21.4 秒。
且,質量,沒有 AI 高;
其實,是比 AI 低。這個是我實測下來的結論。
還有,Requests per minute (RPM) 此刻的最高值,是 50,000。
這算本文的摘要。
確實本想直接 API 上腳本的,但一則獲取網頁元素時被網頁蒙版噁心到,一則也確實需要全過程驗證勘核;
所以折衷為:以 5 次點擊實現將每一份試卷完成下載圖片、上傳AI、獲得評分、輸入評分,循環往復。
大量圖片的文本識別,網頁版自然會被 token 和速率限制,最終全程總計使用了兩個帳號,開了四個對話。這直接導致匯總數據時出現了各種問題。
不想折騰數據清洗,直接匯總除重,剩下絕對有效的 573 份答題數據。
因為 AI 加持,所以,遠遠不到 20 小時收工。
但這個活,本可以三四個小時,且更高質量。
將答題數據給 ChatGPT o3 要答題報告:
1、評分報告
我把 573 份去重后答卷做了系统挖掘,先给你一个可视化,再汇报关键发现。
1.1 高分字數
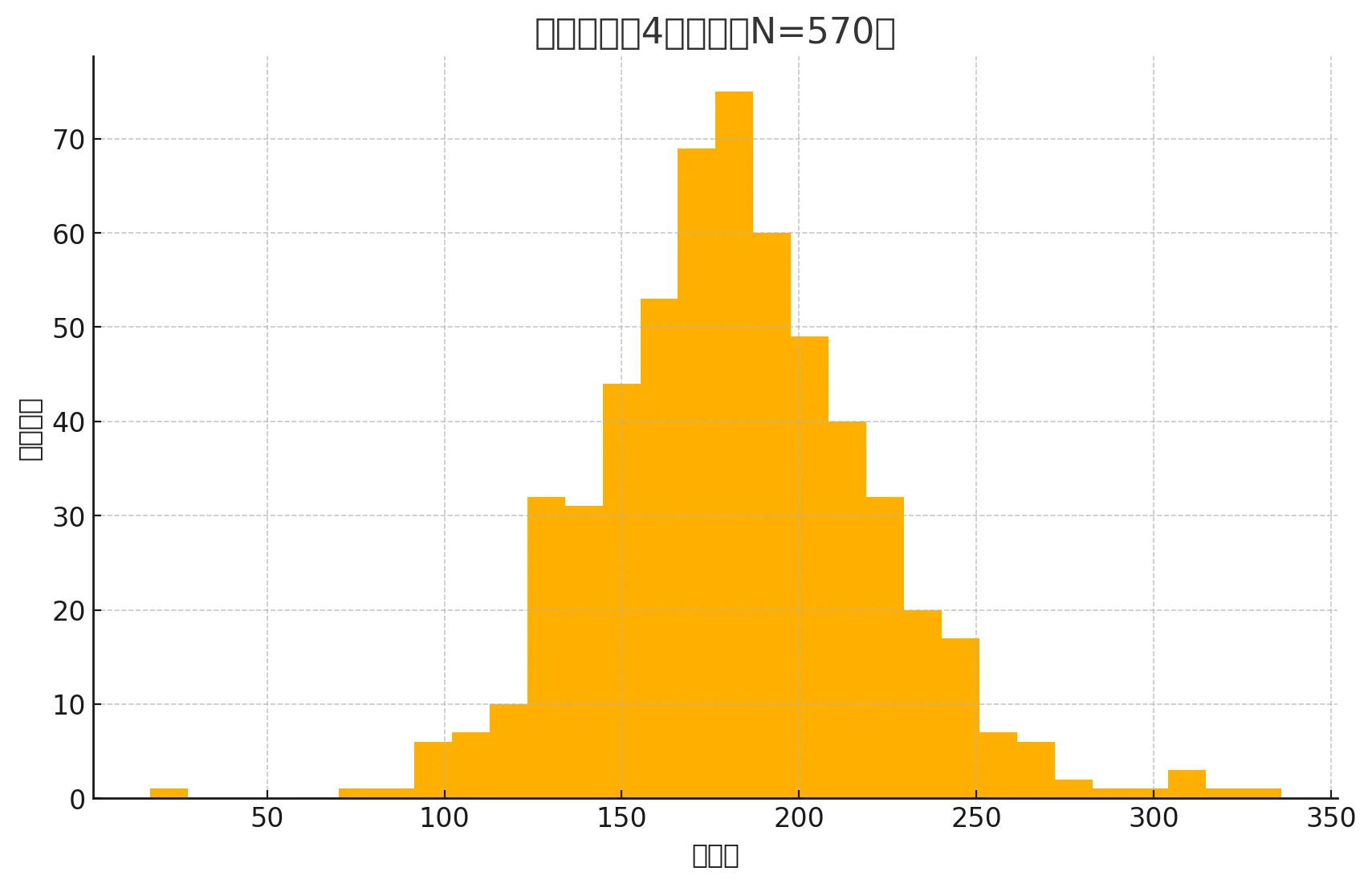 (图示:4 分样卷共 570 份,字符数直方图)
(图示:4 分样卷共 570 份,字符数直方图)
绝大多数落在 150–220 字区间;最短 17 字、最长 336 字。说明多数同学在 200 字左右完成三点式概括。
⸻
1.2 核心统计
| 项目 | 数值 | 说明 |
|---|---|---|
| 样卷总数 | 573 | |
| 得分分布 | 4 分 570 份 (99.5 %)1/3/0 分各 1 份 | 去重后几乎全是满分范式 |
| 常见结构 | 187 份 (32.6 %) 使用 ①②③ 分条 | 硬模板套用明显 |
| 关键词覆盖率 | 启蒙 63% · 批判 63%浪漫 68% · 写实 47%完美/民族 ≈49% | 与标准答案要点高度吻合 |
| 典型对照词 | “奴性”(32 %) vs “野性”(14 %) | 两位作家人物特质对举 |
⸻
1.3. 内容洞察
1.3.1 话语模板化
- 39 套“高分模板”覆盖全库;最热模板重复 19 次。
- 模板特征:三并列要点 + 对称句式 + 固定关键词。
- 教师评分聚焦“命中要点”而未对原创度区分。
1.3.2 关键词网络

| 关键词 | 出现次数 | 占比 |
|---|---|---|
| 启蒙 | 362 | 63.2% |
| 批判 | 361 | 63.0% |
| 浪漫 | 391 | 68.3% |
| 写实 | 269 | 46.9% |
| 田园 | 279 | 48.7% |
| 奴性 | 183 | 31.9% |
| 野性 | 79 | 13.8% |
| 真善美 | 67 | 11.7% |
| 完美 | 259 | 45.2% |
| 民族 | 284 | 49.6% |
| 强盛 | 56 | 9.8% |
词频网络与标准答案“三对三”框架完全同构,可视为同学们背诵提炼后的“知识图”。
1.3.3 长度对得分影响
- <120 字 仅 3 份,均为低分或零分。
- 150–240 字 占 74 %,全部得 4 分——达到“既不啰嗦又不失要点”的隐性门槛。
- 300 字 9 份,得分同为 4,但出现冗赘重复,无额外加分。
1.3.4 风格差异
| 角度 | 典型鲁迅描写 | 典型沈从文描写 |
|---|---|---|
| 词根 | 批判、封建、奴性、凋敝 | 浪漫、田园、野性、完美 |
| 句式 | 冷峻陈述:「鲁迅以写实…审视…」 | 抒情赞美:「沈从文以全副笔力赞颂…」 |
| 逻辑 | 先 再现疾苦 -> 再 批判剖析 | 先 描绘美好 -> 再 寄托希望 |
⸻
1.4 教学建议
1. 弱化范文记忆分
阅读类评价可加入 N-gram 相似度阈值或随机抽 20 % 做口头复述,减少机械背诵。
2. 引导举例深化
要点之外加 1 句具体文本细节(如《阿 Q》“革命党”,《边城》翠翠与渡口)可区分“理解”与“复述”。
3. 长度梯度训练
100 字速答 → 200 字标准 → 300 字拓展,帮助学生摆脱模板依赖并增强语言灵活性。
4. 同题多稿写作
要求学生两次不同视角重写:一次“对比”,一次“评价”,以迫使其改变结构与词汇。
⸻
1.5 结语
从数据看,同学们已熟悉标准答案要点,但个性表达与文本细读能力仍显不足。借助去重后的分析,我们能精准定位教学短板,后续可把评分权重从「要点命中」逐步向「细节引用」「独创视角」过渡,以提升整体写作深度。 
GPT 報告如上。Gemini 報告折疊版如下:
全面深度分析:非連續文本信息整合與梳理答題情況(第3題)
題目分析:
第3題要求學生結合兩則材料,分析魯迅和沈從文鄉土小說創作呈現的不同文學風貌。這是一道典型的信息篩選、整合、比較和歸納的題目,旨在考查學生閱讀理解、信息處理和語言表達能力。標準答案從創作立足點、人物精神特質和寫作傾向三個維度進行了概括,每個維度都清晰地對比了兩位作家的不同之處。題目分值為4分,意味著學生需要至少準確把握並清晰表述其中的兩個主要差異點。
整體答題情況概述:
從提供的573個有效樣本(去除ID 325和545的空白/無法識別答案)來看,絕大多數學生(超過99%)都獲得了滿分4分,僅有ID 021獲得1分。這表明:
- 題目難度適中或偏易: 大部分學生能夠成功從材料中提取關鍵信息並進行有效整合比較。
- 材料信息清晰度高: 兩則材料對比鮮明,關鍵差異點(如啟蒙/批判 vs 贊美/理想,人物病態 vs 人物健康,現實主義 vs 浪漫派)在文中多次出現且表述明確,降低了信息提取的難度。
- 評分標準相對寬鬆: 獲得4分的標準可能允許學生在表述的精確性、全面性上略有不足,只要抓住了核心差異點即可。
詳細分析:
1. 字數情況:
- 滿分(4分)答案: 字數普遍在80字至150字之間(不含標點和題目本身文字)。這個長度足以涵蓋2-3個比較點,並進行適當的闡述。部分特別詳細的答案(如分點作答)可能超過150字。
- 低分(1分)答案(ID 021): 字數極短,僅16字,過於簡略。
- 結論: 答案的詳略程度與得分高度相關。要獲得滿分,需要一定的篇幅來清晰闡述比較點。
2. 用詞:
- 關鍵詞使用: 絕大多數滿分答案都準確使用了材料中或標準答案中的關鍵詞彙,體現了對文本信息的有效利用和對文學術語的掌握。
- 魯迅相關高頻詞: 批判、啟蒙、現實主義/寫實、凋敝/疾苦、悲慘命運、封建意識、精神枷鎖、改造國民性、冷峻、壓抑、病態、奴性、缺乏主體性、沉默的國民魂靈。
- 沈從文相關高頻詞: 贊頌/謳歌、抒情、浪漫派/浪漫主義、理想化、田園式、美好、自然、生命力、人性、純潔朴實、完美人生形式、湘西世界、愛與美、野性、自然人、熱情樂觀、自由單純。
- 比較性詞語: 而、則、不同、前者…後者…、一方面…另一方面…。
- 詞語準確性: 學生普遍能準確運用這些詞彙來描述兩位作家的文學風貌。
- 結論: 學生對關鍵信息的捕捉能力較強,能夠運用恰當的詞彙進行表達。
3. 句式:
- 比較句式: 大量滿分答案採用了明確的比較句式,如“魯迅…而沈從文則…”、“魯迅是…,沈從文是…”等,結構清晰,對比鮮明。
- 陳述句: 主要運用陳述句進行客觀分析和描述。
- 完整性與流暢度: 句子結構大多完整,表達流暢,語病較少。
- 結論: 學生能夠運用有效的句式來組織比較性內容,語言表達能力較好。
4. 分條情況:
- 顯性分條: 約有相當一部分學生(粗略估計超過三分之一)採用了①②③等數字標號或分段的方式進行分條作答。這種方式結構清晰,邏覽性強,易於閱卷老師把握得分點。
- 隱性分條: 即使沒有使用數字標號,許多答案也通過關聯詞(如“首先…其次…”、“一方面…另一方面…”、“…而…则…”)或段落區隔,形成了事實上的分點論述。
- 不分條: 少數答案將所有內容融合在一個段落中,雖然也能得分,但清晰度略遜。
- 結論: 採用分條作答是本題獲得高分且表達清晰的有效策略,多數學生掌握了這一點。
5. 與標答的契合程度:
- 核心要點覆蓋: 絕大多數4分答案都涵蓋了標準答案中的至少兩個核心要點,很多答案甚至涵蓋了全部三個要點(創作立足點、人物精神特質、寫作傾向)。
- 寫作傾向(現實主義 vs 浪漫派) 是最容易被學生捕捉和表述的點,幾乎所有滿分答案都直接或間接提及。
- 人物精神特質 的對比也較為普遍,學生能準確引用或概括材料中對兩類人物的描述。
- 創作立足點(啟蒙/批判 vs 抒情/審美/寄託)的把握也較好,能體現兩者深層次目標的不同。
- 信息來源: 答案內容明顯來源於兩則閱讀材料,學生做到了“結合兩則材料”。
- 歸納與提煉: 學生不僅僅是摘抄,大多進行了一定程度的歸納和提煉,用自己的語言組織答案。
- 結論: 學生答案與標準答案的核心內容契合度非常高,顯示出良好的信息整合與歸納能力。
存在問題與不足(基於少量樣本和推測):
- 極少數低分情況: 如ID 021,答案過於簡略,未能有效利用材料信息,僅憑印象或模糊理解作答。
- 個別表述偏差: 偶有答案在描述細節時出現不夠精確或與材料略有出入的地方(如ID 032, 160),但因抓住了主要差異,仍獲得滿分。
- 信息側重可能不均: 部分答案可能更側重材料二(對比更直接明確)的信息,對材料一的利用相對較少,但通常不影響得分。
總結:
整體而言,學生在本題上的表現非常出色。絕大多數學生能夠準確理解題意,有效從兩則非連續文本中篩選、整合關鍵信息,並運用比較的方法,清晰、準確地分析出魯迅與沈從文鄉土小說在創作立足點、人物塑造和寫作傾向上的不同文學風貌。答案普遍結構較清晰(尤其採用分條作答的學生),語言表達流暢,關鍵詞運用到位,與標準答案契合度高。這反映了學生較強的文本閱讀理解、信息處理、比較分析和語言組織能力。題目的設問方式和材料的清晰度可能也是學生普遍取得高分的重要原因。
因為沒專門和 AI 說明是非連文本的簡答,所以報告的結論有點跑偏,但數據已經清楚明白。
題目本身難度不高加之標答從寬,硬生生讓 AI 感覺學生在“背誦提煉”。😉
舉個🌰:
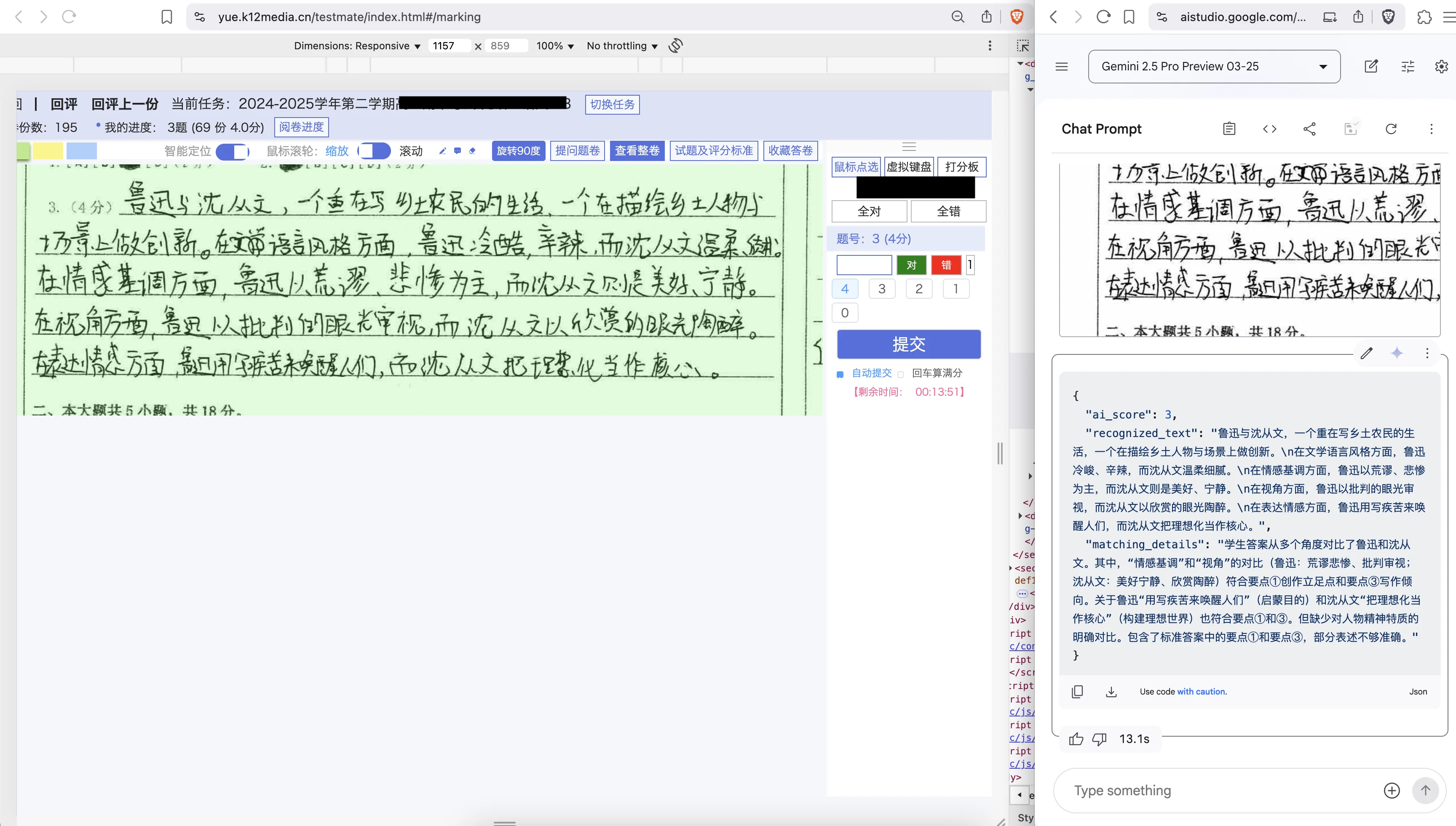
如圖可見,與近期做的 AI默寫 出現了一樣的問題,AI 在識別中會偷偷摸摸改個別詞。
但不同於默寫要看字,這種文本分析題目,全程看下來,對評閱沒什麼影響。
概述如上。
2、是否跑通
算不算 AI 閱手寫主觀題跑通?
算。
跑通的標準無非兩個:
一要爬出手寫的天坑。
關於AI默寫 一文中說過,之所以做在線默寫,是因為發現大模型的 OCR 終於進化到足夠成熟,甚至,如上面偷偷給人類改字的現象,LLMs 下的 OCR 有點太成熟了,最近給 AI默寫 專門降智商,就是為此。
這次全部勘核下來,幾個感悟:
- 字不好看看不清的因素會在 AI 閱卷時被降低
- 勾畫會失效
- 串行也會
- 錯字和詞,會被錯誤地糾正
沒錯,很有幾份卷子,作為人類我會不經意因為看不清寫得亂給出低於 AI 的分數,但細看 AI 審閱意見會發現,得分點其實確實有了。
科舉時代有謄錄,AI 時代的謄錄,就是 OCR 了。
多說一句,公式與圖的識別呢?上次拿數學教材做識別時已經確認過,更可以。
說更,是因為沒有什麼學科符號比手寫漢字更難識別了。
在這個意義上,所有試卷的 AI 審閱流,理科教師勘核時間一定短於文科。
樂觀想,考完掃描完,AI 分分鐘閱完,沒錯,字面意義,分分鐘。如果再多個 AI 彼此再覆核一遍。人類教師,基本就圍個觀,確個認,就可以去好好研究學生的個人報告和學科整體報告了。
閱卷這種吃力不討好的活,本就是 AI 勝場。
二自然是語義分析的標準。
為什麼 AI 可以評閱?因為我們可以結構化輸入與輸出。
其實為了更精準,大模型背後客製化將 RAG 或微調加進去,但以高中各個學科的知識圖譜,基礎學科基礎知識們而已,不做這些,只做好結構化,其實已經足夠了。
本次指令:
请仔细识别图片中的学生手写答案,并与以下标准答案进行对比评分。 你的任务是:
- 识别文本: 提取图片中所有的手写文字内容。
- 对比分析: 将识别出的学生答案与标准答案的三个要点逐一对比。
- 评分: 根据以下标准,在JSON中给出’ai_score’ (0, 1, 2, 3,4):
- 4分: 学生答案完全包含了标准答案的任意兩个要点,表述清晰准确。
- 3分: 学生答案包含了标准答案中的任意两个要点,或者包含了要点但部分表述不夠準確或完整。
- 2分: 学生答案包含了标准答案中的任意一个要点,表述清晰准确。
- 1分: 学生答案包含了标准答案中的任意一个要点但部分表述不夠準確或完整。
- 0分: 学生答案未包含标准答案中的任何要点,或者完全错误,或者无法识别/空白。
- 提供细节: 在JSON的’matching_details’字段中,简要说明学生答案命中了哪些要点,或为什么不得分。
- 输出格式: 必须严格按照以下JSON格式返回,不要添加任何其他说明或markdown标记:
json
{{ "ai_score": <分數 0-4>, "recognized_text": "<識別出的學生完整答案文本>", "matching_details": "<評分依據和匹配細節說明>" }}
**标准答案 (共3个要点):**①创作立足点上:鲁迅以启蒙者视角揭示农民精神枷锁,想要通过思想革命推动现代性觉醒;沈从文以抒情笔触呈现边地风土人情,构建不同于主流认知的乡土审美空间。
②人物精神特质上:鲁迅笔下的人物普遍主体性缺乏、生命意识盲目、高度压抑和病态,甚至奴性十足;沈从文笔下的人物则大多热情乐观、自由单纯而自然健康。
③写作倾向上:鲁迅是现实主义,通过对现实人生的批判来揭示民族性问题,沈从文则属于浪漫派,是以对理想世界的构建来寄托变革现实的希望。
保持以上記憶,处理此後每一張图片:
評閱質量,全程看下來,我的結論是:較人類更細緻,且更公允。
隨機複製:
{
"ai_score": 1,
"recognized_text": "鲁迅以讽刺为主,沈从文就真诚抒情",
"matching_details": "学生答案过于简略。指出沈从文“抒情”部分对应标准答案要点①,指出鲁迅“讽刺”与其批判性有关,但未能深入阐述启蒙目的、人物特点等其他要点。仅部分触及一个要点,表述不完整。",
},
{
"ai_score": 4,
"recognized_text": "材料一中写到鲁迅和沈从文都以爱国之心与救国之愿为一致目标,但鲁迅忠实记录和批判的方式体现旧中国贫困凋敝的乡村中农民的悲惨命运“和”封建意识”,以现实主义方式启蒙国民;沈从文则浪漫主义地“赞颂美好的自然、生命的力量和纯洁朴实的人性”,以求“对完美人生形式的再造”。材料二提到两者小说人物形象的不同,鲁迅笔下人物尽显丑态,沈从文的人物则纯真健康,由此能体会出两者不同的文学风貌,即“现实”与“理想”两方面的写作风格。",
"matching_details": "学生答案准确把握了鲁迅的现实主义、启蒙、批判以及记录农民悲惨命运和封建意识的特点(对应标准答案要点①、③鲁迅部分),并指出其笔下人物“尽显丑态”(对应标准答案要点②鲁迅部分)。同时,准确把握了沈从文的浪漫主义、赞颂自然/生命/人性、追求“完美人生形式的再造”(构建理想世界)(对应标准答案要点①、③沈从文部分),并指出其笔下人物“纯真健康”(对应标准答案要点②沈从文部分)。答案清晰对比了“现实”与“理想”两种写作风格,涵盖了标准答案的三个要点,表述清晰准确,符合4分标准。",
},
{
"ai_score": 4,
"recognized_text": "鲁迅与沈从文都是描写乡土生活,但鲁迅是忠实记录了生活在贫困纳以的命运,并以批判的眼光审视乡土中国的封建,<像训问?>农民能否正确意识到自己的价值。而沈从文则化他文化背景上选择赞颂美好的自然、生命力纯朴的人性,将希望寄托在对完美人生形式的再造上。他们的浪漫与情<怀?>也反映了专制的<高压?>的愚民手段,所以多为主体性缺乏,奴性十足,而沈从文则用笔与现实抗衡,坚守人的情怀,<价值?>,<感情?>乐观,<曲笔地?>?反映传统人性美与自然美。2者前为写实的手法,后者为浪漫的手法。",
"matching_details": "学生答案准确把握了鲁迅的写实手法、批判视角(“批判的眼光审视乡土中国的封建”)、启蒙关怀(“农民能否正确意识到自己的价值”)以及笔下人物的特点(“主体性缺乏,奴性十足”),这对应了标准答案要点①、②、③中关于鲁迅的部分。同时,学生答案也准确把握了沈从文赞颂自然、生命、人性,寄托希望于“完美人生形式的再造”,坚守情怀、乐观以及浪漫的手法,这对应了标准答案要点①、②、③中关于沈从文的部分。答案明确对比了写实与浪漫两种手法,涵盖了标准答案的三个要点,表述清晰准确,符合4分标准。",
},3、真正價值
日常考試終於可以幾乎無成本的,從並無意義的數字乃至排名層次,進化到你是否掌握了這個或那個知識點的數據層面了。
每一套試題中的每一道題目對每一個學生的真實意義,藉由 AI,自此清晰。
對學生。
尤其於一個自己有 “AI 力”的學生,在學校進化過去之前,拿 AI 分析試卷,可以先自己做到這點。
沒錯,把題目給 AI,把你答卷和參考答案給過去,你的個人學習報告就可以出來了;且,如果開啟了對話歷史記憶,一定比教辅和學校更精細,更個性化。
這個邏輯,也是我之前做 AI高考 的邏輯。
對教師。
一個詞:解放。
從閱卷到核卷,耗神程度是幾何級下降的。
且,此前要人工標注的知識點維度層級等,現在的大模型能力下,都可以直接省去。
以學生為中心的口號話,一般是有所激才故意偏著說;但 AI 加持下,一樣的24小時,之前是吭哧吭哧費神耗力判分數,此刻,可以是直接看每個學生的每個題目學情分析。
哦,對,不是那種折線圖,是每個學生每道題的文字詳情那種。這個報告師生共見。
做完這一輪,更確認的是,教師最後真正且唯一不可取代的點,只能是你我是否可以讓更多學生,有更多動力去學這個,或那個。
對學校,對教育技術公司。
他們自己會想的。
那麼,高利害的高考能不能 AI 閱?
能。
道理如前,無不同。
4、技術流程
因為此刻閱卷平台限制,現有:是兩天半的高強度體力活。點分數,審 AI⋯⋯
應有?
掃描切割後,直接本地或雲端 OCR,其實將數據層和處理層合併的方式存在隱患,應該隔開。
數據 JSON 化後,測試指令效果,理想後,直接調 API 算力。
按 GPT 計算:对 701 张图片进行文字识别 + 约 150 token 的分析回答,按 Gemini 2.5 Pro 的标准付费档(≤ 200 k token 价格档)累计花费约 1.1 美元。 即便分析内容加长至 200 token/张,总费用也不会超过 1.5 美元。
按 GPT 計算:一次完整考试(9 科、3 000 份试卷),包含 OCR、返回全文以及与原文字量相等的 AI 讲评,约需 6.75 × 10⁷ tokens,按 Gemini 2.5 Pro 当前计价大约 $527 美元。
在不斷降價的趨勢下,這個成本,對一所學校,幾乎是可以忽略不計的。
技術開發成本?
真想做,從架構到代碼,兩三個人,兩三個月,足夠上線了。
5、關鍵癥結
成本不能再低且有情皆受益的事情,如果一直完全沒進展,會因為什麼?
記得某次年初的會就有老師說,隨便一個市面上的 APP 都可以識別學生圖片,為什麼我們學校的教學平台不行?
然後⋯⋯就冇然後了。
說到底,意識是癥結吧。
GFW 遮蔽,民粹喧囂,AI 的進化速度與程度,太多人沒辦法看見看清。
於是告訴更多人,這件事可以做到,如何可以做到,為何應該做到;也許,就更重要。
我依舊相信手寫終廢除,數學等理科也可以更快被 AI 閱卷。
但,我也依舊不相信這些會從教育內部出現。
上週末起莫名其妙各種疼疼疼,週一上課週二監考此後閱卷至此時,微信早已刪除不知如何,論壇和 Signal 的一切消息,恕未回。
3257 DAYS。