在意分數當然是對的,但你為什麼在意分數?為了在意而在意,純愛分數?
不是的吧?你只是在意高考分數。
你當然該在意高考,高考高利害;儘管對北上廣深高中生,這個高利害也真不是非那幾個211985不可。
那下一個問題,如何真在意高考?當然是不斷訓練自己拿更高分。
有些學生和大多數家長出局,其實就是從上面這句。
訓練和日常考試需要指向高考才有意義,不指向高考的訓練和考試,分數再高對高考也沒價值。
這是一個大前提。認下這點,後續討論才能展開。
家長之所以在這裡基本都出局了,是因為無法真的分析題目和高考關聯程度究竟如何,家長看到的只是數字,數字的真正意義大多看不到,於是急了也是白急,甚至惹毛了孩子的話,大多數情況還不如不急。
對,日常訓練,包括海淀統考更包括各校自己命題,和高考的關聯程度,都並不天然和高考真的相關;
家長默認你日常考好了高考就會好的邏輯,在語文學科,幾乎是不成立的。
這也是語文分數很玄學的原因之一。
如何正確在意呢?簡單,既然是為了高考分數,尺度標準就是唯一的,高考真題!
一套日常試題的價值和意義,只在於這點。
分數和校內排名,在你所在意的高考面前確實沒有意義。因為最終錄取是全市排名,你校正數第一可能依舊全市倒數,你校倒數第一也可能是全市前排。家長拼命進所謂好學校,也是為了這個默認。但多好才是真的好呢⋯⋯
卷從來都有理由,但有理由,並不意味著都是對的⋯⋯
回到功利。
真題是王道,日常考題和此後三年真題一致程度或至少方向上,愈高愈一致,自然就越有價值。
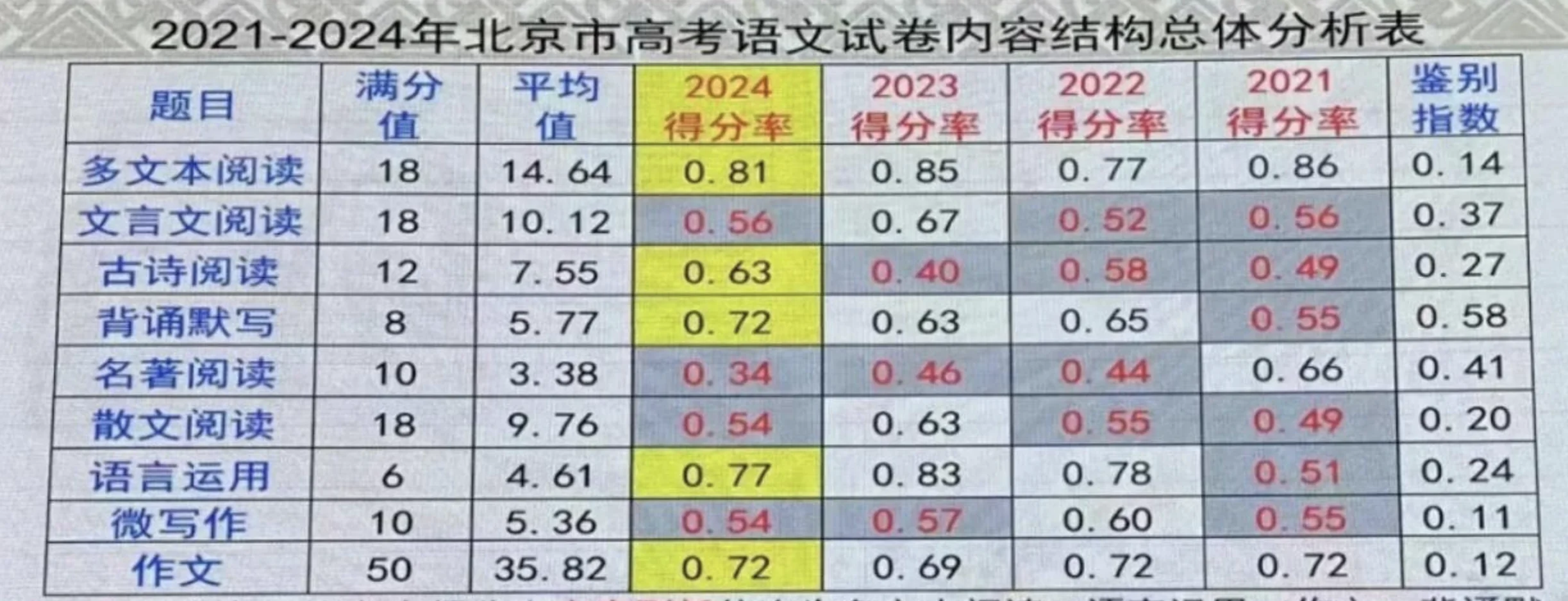
本次考試的一致程度分析表:
| 題號題型 | 分值 | 高考價值 | 備註 |
|---|---|---|---|
| 1、注音 | 1 | 0 | 高考不考 |
| 2、字形 | 1 | 0 | 高考不考 |
| 3、成語 | 1 | 0 | 高考不考 |
| 4、語病 | 1 | 0 | 語言基礎運用有6分但不是這樣考 |
| 5、文常 | 1 | 0 | 高考不考 |
| 6、文言實詞 | 1 | 1 | 課內文言實詞,高考文言文第一題考 |
| 7、文言虛詞 | 1 | 1 | 課內文言實詞,高考文言文第二題考 |
| 8、文言句式 | 1 | 0 | 高考不考 |
| 9、語言基礎運用 | 2 | 1 | 高考內容 |
| 10、語言基礎運用 | 2 | 1 | 高考內容 |
| 11、文言文文言實詞 | 2 | 1 | 課內文言實詞,高考文言文第一題考 |
| 12、文言文文言虛詞 | 2 | 1 | 課內文言實詞,高考文言文第二題考 |
| 13、文言句義 | 2 | 1 | 課內文言實詞,高考文言文第三題考 |
| 14、文言文義 | 2 | 1 | 課內文言實詞,高考文言文第四題考 |
| 15、文言簡答 | 4 | 1 | 課內文言實詞,高考文言文第五題考 |
| 16、論語/紅樓夢 | 6 | 1 | 高考內容 |
| 171819、古詩詞 | 2+2+4 | 1 | 高考內容 |
| 20、默寫 | 10 | 1 | 高考內容 |
| 21-24現代文 | 12 | 0 | 小說/高考不考 |
| 25、大作文 | 40 | 1 | 高考內容 |
本次考試合計有價值題目的分數總值:82 分。包含:
文言文 14 分+古詩詞 8 分+整本書 6 分+默寫 10 分+語言基礎運用 4 分+大作文 40 分。
開學至今,各種作業的唯一指向就是讓你熟悉高考真題,上述的表你能自己列時才合格。
這 82 內,默寫需要滿分 10,文言文需要 10+,古詩詞 6+,整本書 6,默寫 10,語言基礎運用 4,大作文 32+;達不到這個分項分,就需要逐個項目繼續做高考真題。
亦即,這套題目,刪除無意義題目,滿分 82 的題目內,你需要拿到 78 分。 換言之,如下幾種需要各自反思不同點:
- 總分很高但不是該拿的。
- 該拿的分數沒拿到。
| 題號題型 | 分值 | 高考分值 | 備註 |
|---|---|---|---|
| 文言文 | 14 | 18 | 最多 -3 |
| 古詩詞 | 8 | 12 | 最多 -3 |
| 論語/紅樓夢 | 6 | 6或10 | 必須滿 |
| 默寫 | 10 | 8 | 必須滿 |
| 語言基礎運用 | 4 | 6 | 必須滿 |
| 大作文 | 40 | 50 | 45+ |
哪一項分數不足,就繼續把高考真題的對應項目,繼續從2025年做回2002年。
作文在平台能看到自己電子版是吧?
兩個選擇:
1、願意改這份,你錄電子版,發我,我改,你分析我為什麼這麼改。
2、不要這篇,寫2025高考作文,你寫,我改,你分析我為什麼這麼改。
個人保持一貫建議,選真題作文。
還有兩個關鍵:
考試時間 150 分鐘,要自己訓練。一分一分鐘,很多學校在應試該有的細節上,從來拉,何況拉滿⋯⋯
非連/微寫作/現代文,本次沒考⋯⋯
這是一份根據您提供的考試資料(總分 150 分)生成的學生成績分析報告。報告已抹去學生姓名,學號,並將高考價值分數(GKV,滿分 82 分)轉換為 150 分制進行對比。
關鍵指標說明
- GKV (滿分 82): 高考價值分數 (GKV) 總計 82 分。目標分數為 78 分。
- GKV (滿分 150): 將 GKV 82 分轉換為 150 分制的得分 $ \frac{\text{GKV}}{82} \times 150 $
- 必須滿分項: 指默寫 (Q20,10 分) 和語言基礎運用 (Q9+Q10,4 分)。這兩項是必須拿到滿分的基礎項目。
- 建議方向: 基於 GKV 是否達到目標 (78分) 和必須滿分項的失分情況,提出反思方向。
| 總分 | GKV (滿分 82) | GKV (滿分 150) | 必須滿分項得分 (Q9+Q10/4, Q20/10) | 分析與建議方向 |
|---|---|---|---|---|
| 58 | 51 | 93.41 | Q9+Q10: 2/4;Q20: 1/10 | GKV 偏低。默寫嚴重失 9 分,必須立即針對默寫真題進行強化訓練。 |
| 61 | 54 | 98.78 | Q9+Q10: 2/4;Q20: 7/10 | GKV 低。基礎分未達滿分,需反思基礎知識掌握情況。 |
| 60 | 54 | 98.78 | Q9+Q10: 0/4 (滿分必須);Q20: 6/10 | GKV 低。語言基礎運用 0 分,屬於「該拿的分數沒拿到」。需將對應高考真題從 2025 年做回 2002 年。 |
| 76 | 67 | 122.56 | Q9+Q10: 2/4;Q20: 7/10 | 總分很高,但 GKV 僅 67 分。基礎分未滿分,屬於總分很高但不是該拿的情況,需反思基礎分失誤。 |
| 68 | 62 | 113.41 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。需補齊語言基礎運用失分,以提升 GKV。 |
| 59 | 50 | 91.46 | Q9+Q10: 0/4 (滿分必須);Q20: 9/10 | GKV 偏低。語言基礎運用 0 分,必須立即針對 Q9/Q10 類型的真題進行訓練。 |
| 60 | 56 | 102.44 | Q9+Q10: 4/4 (滿分);Q20: 3/10 | 語言基礎滿分。但默寫嚴重失 7 分,是 GKV 偏低的主因,急需進行默寫真題強化訓練。 |
| 58 | 59 | 107.93 | Q9+Q10: 4/4 (滿分);Q20: 5/10 | 語言基礎滿分。但默寫失 5 分,GKV 偏低。 |
| 69 | 63 | 115.24 | Q9+Q10: 2/4;Q20: 6/10 | GKV 僅 63 分。默寫失 4 分,語言基礎失 2 分,必須滿分處失分多。 |
| 64 | 60 | 109.76 | Q9+Q10: 2/4;Q20: 8/10 | GKV 偏低。基礎分均未滿分要求,需將重點放在必須滿分項目上。 |
| 64 | 60 | 109.76 | Q9+Q10: 2/4;Q20: 5/10 | GKV 低。默寫失 5 分,基礎分流失嚴重。 |
| 71 | 63 | 115.24 | Q9+Q10: 4/4 (滿分);Q20: 10/10 (滿分) | 基礎滿分表現出色。GKV 總分偏低,顯示失分來自文言文、古詩詞或大作文。 |
| 70 | 67 | 122.56 | Q9+Q10: 4/4 (滿分);Q20: 4/10 | 默寫嚴重失 6 分,屬於「該拿的分數沒拿到」。 |
| 62 | 58 | 106.10 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。需補齊語言基礎運用的 2 分失分。 |
| 58 | 53 | 96.95 | Q9+Q10: 2/4;Q20: 4/10 | GKV 偏低。默寫失分嚴重,必須大量補做真題。 |
| 68 | 61 | 111.59 | Q9+Q10: 0/4 (滿分必須);Q20: 8/10 | 語言基礎運用 0 分,屬於必須補救的基礎性失誤。 |
| 70 | 66 | 120.73 | Q9+Q10: 2/4;Q20: 7/10 | GKV 尚可,但基礎分仍需達到滿分要求。 |
| 55 | 60 | 109.76 | Q9+Q10: 2/4;Q20: 8/10 | GKV 尚可,但基礎項目仍失分。 |
| 71 | 67 | 122.56 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。需補齊語言基礎運用失分。 |
| 69 | 63 | 115.24 | Q9+Q10: 0/4 (滿分必須);Q20: 8/10 | 語言基礎運用 0 分,必須立即針對真題進行訓練。 |
| 69 | 68 | 124.39 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。但語言基礎運用失 2 分,需反思。 |
| 72 | 68 | 124.39 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。語言基礎運用失分,需努力達到 4 分滿分。 |
| 80 | 72 | 131.71 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 總分高,GKV 達 72 分。默寫滿分。但語言基礎運用失 2 分,是衝擊 78 分目標的關鍵。 |
| 65 | 62 | 113.41 | Q9+Q10: 0/4 (滿分必須);Q20: 10/10 (滿分) | 默寫滿分。但語言基礎運用 0 分,是 GKV 上升的嚴重障礙。 |
| 73 | 66 | 120.73 | Q9+Q10: 4/4 (滿分);Q20: 9/10 | 語言基礎滿分。默寫失 1 分,屬於不應該的失分,需反思。 |
| 60 | 54 | 98.78 | Q9+Q10: 0/4 (滿分必須);Q20: 2/10 | GKV 嚴重偏低。基礎分失 12 分 (4+8),必須進行高考真題的強化訓練。 |
| 73 | 71 | 129.88 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | GKV 71 分,接近目標。默寫滿分。語言基礎運用失 2 分,應保證滿分。 |
| 75 | 70 | 128.05 | Q9+Q10: 0/4 (滿分必須);Q20: 7/10 | 總分很高。但基礎分失分嚴重:默寫失 3 分,語言基礎運用 0 分。 |
| 76 | 70 | 128.05 | Q9+Q10: 2/4;Q20: 8/10 | GKV 達 70 分。默寫失 2 分,語言基礎失 2 分,屬於「該拿的分數沒拿到」。 |
| 65 | 60 | 109.76 | Q9+Q10: 2/4;Q20: 7/10 | GKV 偏低。基礎分失分點在默寫和語言應用,需反思。 |
| 69 | 66 | 120.73 | Q9+Q10: 0/4 (滿分必須);Q20: 6/10 | 默寫失 4 分,語言基礎運用 0 分,基礎分失 8 分,屬於必須補救的項目。 |
| 55 | 52 | 95.12 | Q9+Q10: 0/4 (滿分必須);Q20: 8/10 | GKV 偏低。語言基礎運用 0 分,需大量訓練對應真題。 |
| 65 | 61 | 111.59 | Q9+Q10: 2/4;Q20: 3/10 | GKV 低。默寫失 7 分,是最大的基礎分漏洞。 |
| 70 | 66 | 120.73 | Q9+Q10: 2/4;Q20: 7/10 | 默寫和語言基礎運用均有失分,應以滿分為目標。 |
| 71 | 68 | 124.39 | Q9+Q10: 4/4 (滿分);Q20: 8/10 | 語言基礎滿分。但默寫失 2 分,導致 GKV 未能達到高分區。 |
| 69 | 66 | 120.73 | Q9+Q10: 2/4;Q20: 5/10 | GKV 偏低。默寫失 5 分,基礎分流失嚴重。 |
| 80 | 67 | 122.56 | Q9+Q10: 0/4 (滿分必須);Q20: 10/10 (滿分) | 總分高。默寫滿分。但語言基礎運用 (Q9, Q10) 獲得 0 分,屬於「該拿的分數沒拿到」。這是衝擊 GKV 目標(78 分)的關鍵阻礙,必須立即將高考真題的對應項目從 2025 年做回 2002 年。 |
| 65 | 63 | 115.24 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。GKV 尚可,需補齊語言基礎運用失分。 |
| 67 | 64 | 117.07 | Q9+Q10: 0/4 (滿分必須);Q20: 7/10 | 默寫失分,語言基礎運用 0 分,大量基礎分流失。 |
| 39 | 30 | 54.88 | Q9+Q10: 0/4 (滿分必須);Q20: 0/10 (嚴重失分) | GKV 極低,基礎分失 14 分。情況緊急,必須將對應真題從 2025 年做回 2002 年。 |
| 65 | 57 | 104.27 | Q9+Q10: 4/4 (滿分);Q20: 0/10 (嚴重失分) | 語言基礎滿分。但默寫 0 分,屬於「該拿的分數沒拿到」的極端情況,需立即針對默寫進行強化訓練。 |
| 68 | 65 | 118.90 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。GKV 尚可,需將語言基礎運用失的 2 分補齊。 |
| 70 | 61 | 111.59 | Q9+Q10: 2/4;Q20: 8/10 | GKV 偏低。基礎分項目均有失分,應以滿分為目標。 |
| 69 | 67 | 122.56 | Q9+Q10: 0/4 (滿分必須);Q20: 10/10 (滿分) | 默寫滿分。GKV 達 67 分。但語言基礎運用 0 分,是衝擊 78 分目標的關鍵阻礙。 |
| 59 | 59 | 107.93 | Q9+Q10: 2/4;Q20: 7/10 | GKV 尚可。基礎分失分點多,需全面補強。 |
| 62 | 61 | 111.59 | Q9+Q10: 0/4 (滿分必須);Q20: 5/10 | GKV 偏低。默寫失 5 分,語言基礎運用 0 分。 |
| 72 | 68 | 124.39 | Q9+Q10: 2/4;Q20: 7/10 | GKV 接近 70 分。基礎分未滿分,需持續提升默寫能力。 |
| 64 | 62 | 113.41 | Q9+Q10: 2/4;Q20: 8/10 | GKV 偏低。基礎分未滿分,需反思。 |
| 58 | 56 | 102.44 | Q9+Q10: 2/4;Q20: 5/10 | GKV 偏低。默寫失 5 分,必須補強。 |
| 63 | 63 | 115.24 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。GKV 尚可,需補齊語言基礎失分。 |
| 23 | 19 | 34.76 | Q9+Q10: 2/4;Q20: 0/10 (嚴重失分) | GKV 極低 (19分)。默寫 0 分。情況非常緊急,必須將對應真題做回 2002 年。 |
| 69 | 67 | 122.56 | Q9+Q10: 4/4 (滿分);Q20: 6/10 | 語言基礎滿分。但默寫失 4 分,屬於「該拿的分數沒拿到」,需立刻補救。 |
| 69 | 67 | 122.56 | Q9+Q10: 2/4;Q20: 8/10 | GKV 尚可。基礎分均有失分,需提升至滿分。 |
| 70 | 69 | 126.22 | Q9+Q10: 2/4;Q20: 8/10 | GKV 尚可。基礎分均有失分,必須滿分的基礎分不能有失誤。 |
| 75 | 71 | 129.88 | Q9+Q10: 2/4;Q20: 8/10 | GKV 達 71 分,總分高。默寫失 2 分,語言基礎失 2 分,這 4 分是衝擊 78 分目標的關鍵。 |
| 60 | 56 | 102.44 | Q9+Q10: 0/4 (滿分必須);Q20: 8/10 | GKV 偏低。語言基礎運用 0 分,需反思。 |
| 59 | 55 | 100.00 | Q9+Q10: 2/4;Q20: 5/10 | GKV 偏低。默寫失 5 分,必須加強。 |
| 70 | 68 | 124.39 | Q9+Q10: 2/4;Q20: 9/10 | GKV 尚可。默寫和語言基礎運用均有失分,需達到滿分要求。 |
| 56 | 51 | 93.41 | Q9+Q10: 0/4 (滿分必須);Q20: 4/10 | GKV 極低。默寫失 6 分,語言基礎運用 0 分。 |
| 62 | 64 | 117.07 | Q9+Q10: 2/4;Q20: 8/10 | GKV 尚可。基礎分未達滿分。 |
| 70 | 65 | 118.90 | Q9+Q10: 0/4 (滿分必須);Q20: 9/10 | 默寫僅失 1 分。但語言基礎運用 0 分,屬於基礎性失誤,必須立即補救。 |
| 74 | 66 | 120.73 | Q9+Q10: 4/4 (滿分);Q20: 6/10 | 語言基礎滿分。但默寫失 4 分,屬於「該拿的分數沒拿到」。 |
| 75 | 70 | 128.05 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。GKV 達 70 分。語言基礎運用失 2 分,是達到 78 分目標的障礙。 |
| 71 | 67 | 122.56 | Q9+Q10: 0/4 (滿分必須);Q20: 9/10 | 默寫失 1 分。但語言基礎運用 0 分,必須立即進行針對性訓練。 |
| 67 | 64 | 117.07 | Q9+Q10: 2/4;Q20: 8/10 | 基礎分均有失分,需提升至滿分。 |
| 69 | 66 | 120.73 | Q9+Q10: 2/4;Q20: 5/10 | GKV 偏低。默寫失 5 分,必須將重心放回基礎背誦和應用上。 |
| 74 | 65 | 118.90 | Q9+Q10: 0/4 (滿分必須);Q20: 6/10 | 總分很高。默寫失 4 分,語言基礎運用 0 分,必須全面反思學習方向。 |
| 64 | 62 | 113.41 | Q9+Q10: 2/4;Q20: 6/10 | 默寫失 4 分,是 GKV 偏低的主因。 |
| 64 | 60 | 109.76 | Q9+Q10: 2/4;Q20: 5/10 | 默寫失 5 分,GKV 偏低,需大量補做真題。 |
| 84 (最高) | 73 (最高) | 133.54 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 總分及 GKV 最高。默寫滿分。但語言基礎運用仍失 2 分,這 2 分屬於必須拿到的分數。 |
| 70 | 66 | 120.73 | Q9+Q10: 2/4;Q20: 8/10 | GKV 尚可。默寫和語言基礎運用均未滿分。 |
| 67 | 64 | 117.07 | Q9+Q10: 2/4;Q20: 10/10 (滿分) | 默寫滿分。GKV 尚可,需補齊語言基礎運用失的 2 分。 |
| 70 | 67 | 122.56 | Q9+Q10: 2/4;Q20: 8/10 | 基礎分均有失分,需提升。 |
| 57 | 56 | 102.44 | Q9+Q10: 0/4 (滿分必須);Q20: 5/10 | GKV 偏低。默寫失 5 分,語言基礎運用 0 分,基礎訓練嚴重不足。 |
| 76 | 66 | 120.73 | Q9+Q10: 4/4 (滿分);Q20: 5/10 | 總分高。語言基礎滿分。但默寫失 5 分,屬於「該拿的分數沒拿到」,是嚴重的基礎性失分。 |
| 班級 | 序號 | 總分 | GKV(82) | GKV→150 | 語基得分(4) | 默寫得分(10) | 分析與建議方向 |
|---|---|---|---|---|---|---|---|
| 格物3班 | 1 | 58 | 45 | 82.3 | 2 | 1 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 33 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 35/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 2 | 61 | 50 | 91.5 | 2 | 2 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 28 分。 語基(2/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 29/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 3 | 60 | 55 | 100.5 | 0 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 23 分。 語基(0/4)和默寫(2/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 4 | 76 | 64 | 117.1 | 2 | 3 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 語基(2/4)和默寫(3/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 5 | 68 | 57 | 104.3 | 2 | 3 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 21 分。 語基(2/4)和默寫(3/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 6 | 59 | 49 | 89.6 | 0 | 4 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 29 分。 語基(0/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(4/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 25/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 格物3班 | 7 | 60 | 52 | 95.1 | 4 | 3 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 默寫(3/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 8 | 58 | 53 | 96.9 | 4 | 1 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 25 分。 默寫(1/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 24/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 格物3班 | 9 | 69 | 58 | 106.1 | 4 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 20 分。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 10 | 64 | 56 | 102.4 | 2 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 22 分。 語基(2/4)和默寫(2/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 25/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 格物3班 | 11 | 64 | 56 | 102.4 | 4 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 22 分。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 12 | 71 | 61 | 111.6 | 4 | 3 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 17 分。 默寫(3/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 13 | 70 | 59 | 107.9 | 4 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 19 分。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 格物3班 | 14 | 62 | 48 | 87.8 | 2 | 0 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 30 分。 語基(2/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(0/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 25/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 格物3班 | 15 | 58 | 45 | 82.3 | 4 | 1 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 33 分。 默寫(1/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 格物3班 | 16 | 68 | 57 | 104.3 | 2 | 1 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 21 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 17 | 70 | 56 | 102.4 | 4 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 22 分。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 18 | 55 | 48 | 87.8 | 2 | 1 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 30 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 19 | 71 | 61 | 111.6 | 2 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 17 分。 語基(2/4)和默寫(2/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 20 | 69 | 62 | 113.4 | 2 | 2 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 16 分。 語基(2/4)和默寫(2/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 21 | 69 | 58 | 106.1 | 2 | 1 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 20 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 29/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 22 | 72 | 60 | 109.8 | 2 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 語基(2/4)和默寫(2/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 23 | 80 | 66 | 120.7 | 4 | 2 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 12 分。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 24 | 65 | 52 | 95.1 | 2 | 0 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 語基(2/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(0/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 25/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 格物3班 | 25 | 73 | 60 | 109.8 | 4 | 4 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 語基與默寫已守住基本盤,可以把精力更多投向文言、古詩詞和作文。 大作文約 35/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 26 | 60 | 60 | 109.8 | 2 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 語基(2/4)和默寫(2/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 27 | 75 | 65 | 118.9 | 4 | 3 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 13 分。 默寫(3/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 36/40,基本達到當前要求,可以向 38+ 衝刺。 |
| 格物3班 | 28 | 76 | 64 | 117.1 | 4 | 4 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 語基與默寫已守住基本盤,可以把精力更多投向文言、古詩詞和作文。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 29 | 65 | 56 | 102.4 | 2 | 1 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 22 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 30 | 70 | 64 | 117.1 | 4 | 2 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 31 | 69 | 64 | 117.1 | 4 | 3 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 默寫(3/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 32 | 73 | 61 | 111.6 | 2 | 4 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 17 分。 語基(2/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(4/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 35/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 33 | 65 | 58 | 106.1 | 2 | 1 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 20 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 34 | 69 | 60 | 109.8 | 4 | 3 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 默寫(3/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 35 | 69 | 64 | 117.1 | 2 | 1 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 35/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 格物3班 | 36 | 69 | 64 | 117.1 | 4 | 2 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 默寫(2/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 格物3班 | 37 | 80 | 70 | 128.0 | 0 | 4 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 8 分。 語基(0/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(4/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 37/40,基本達到當前要求,可以向 38+ 甚至滿分衝刺。 |
| 致知3班 | 1 | 65 | 55 | 100.5 | 2 | 1 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 23 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 2 | 67 | 55 | 100.5 | 0 | 7 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 23 分。 語基(0/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(7/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 25/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 3 | 39 | 21 | 38.4 | 0 | 0 | 目前高考向度分數偏低,建議儘快梳理知識與題型,調整復習節奏。 距離目標 GKV 78 還差約 57 分。 語基(0/4)和默寫(0/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 25/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 4 | 65 | 52 | 95.1 | 0 | 8 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 語基(0/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(8/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 5 | 68 | 60 | 109.8 | 2 | 1 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 29/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 6 | 70 | 57 | 104.3 | 4 | 3 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 21 分。 默寫(3/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 26/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 7 | 69 | 59 | 107.9 | 2 | 2 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 19 分。 語基(2/4)和默寫(2/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 8 | 59 | 47 | 86.0 | 2 | 1 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 31 分。 語基(2/4)和默寫(1/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 9 | 62 | 52 | 95.1 | 2 | 5 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 語基(2/4)和默寫(5/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 10 | 72 | 61 | 111.6 | 2 | 7 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 17 分。 語基(2/4)和默寫(7/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 33/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 11 | 64 | 52 | 95.1 | 2 | 8 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 語基(2/4)和默寫(8/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 29/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 12 | 58 | 48 | 87.8 | 2 | 5 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 30 分。 語基(2/4)和默寫(5/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 26/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 13 | 63 | 52 | 95.1 | 2 | 10 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 語基(2/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 大作文約 29/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 14 | 23 | 15 | 27.4 | 0 | 0 | 目前高考向度分數偏低,建議儘快梳理知識與題型,調整復習節奏。 距離目標 GKV 78 還差約 63 分。 語基(0/4)和默寫(0/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 24/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 15 | 69 | 58 | 106.1 | 4 | 6 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 20 分。 默寫(6/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 16 | 69 | 56 | 102.4 | 2 | 8 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 22 分。 語基(2/4)和默寫(8/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 17 | 70 | 60 | 109.8 | 2 | 8 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 語基(2/4)和默寫(8/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 18 | 75 | 64 | 117.1 | 4 | 8 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 默寫(8/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 致知3班 | 19 | 60 | 49 | 89.6 | 0 | 8 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 29 分。 語基(0/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(8/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 24/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 20 | 59 | 49 | 89.6 | 4 | 5 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 29 分。 默寫(5/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 21 | 70 | 60 | 109.8 | 2 | 9 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 語基(2/4)和默寫(9/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 22 | 56 | 48 | 87.8 | 0 | 4 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 30 分。 語基(0/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(4/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 23 | 62 | 52 | 95.1 | 2 | 8 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 語基(2/4)和默寫(8/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 24 | 70 | 62 | 113.4 | 2 | 8 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 16 分。 語基(2/4)和默寫(8/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 致知3班 | 25 | 67 | 58 | 106.1 | 4 | 8 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 20 分。 默寫(8/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 29/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 26 | 69 | 63 | 115.2 | 4 | 5 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 15 分。 默寫(5/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 36/40,基本達到當前要求,可以向 38+ 衝刺。 |
| 致知3班 | 27 | 74 | 64 | 117.1 | 4 | 6 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 14 分。 默寫(6/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 34/40,基本達到當前要求,可以向 35+ 甚至 38+ 衝刺。 |
| 致知3班 | 28 | 64 | 51 | 93.3 | 2 | 6 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 27 分。 語基(2/4)和默寫(6/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 29 | 64 | 52 | 95.1 | 4 | 5 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 默寫(5/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 30 | 71 | 60 | 109.8 | 4 | 9 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 默寫(9/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 31 | 71 | 63 | 115.2 | 2 | 8 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 15 分。 語基(2/4)和默寫(8/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 33/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 32 | 62 | 53 | 97.0 | 4 | 8 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 25 分。 默寫(8/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 28/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 33 | 84 | 70 | 128.0 | 2 | 10 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 8 分。 語基(2/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 大作文約 35/40,基本達到當前要求,可以向 38+ 衝刺。 |
| 致知3班 | 34 | 70 | 61 | 111.6 | 4 | 8 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 17 分。 默寫(8/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 30/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 35 | 67 | 50 | 91.5 | 2 | 10 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 28 分。 語基(2/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 大作文約 25/40,是主要提分空間,建議從審題立意和結構入手,每週至少寫一篇真題。 |
| 致知3班 | 36 | 70 | 60 | 109.8 | 2 | 8 | 高考向度屬中游,再抬一個檔位就能接近目標線。 距離目標 GKV 78 還差約 18 分。 語基(2/4)和默寫(8/10)都未滿,先把這兩塊當作『送分題』天天練。 大作文約 32/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 37 | 57 | 52 | 95.1 | 0 | 5 | 高考向度偏弱,需要有意識地往真題標準靠攏。 建議先把基礎題型做穩,再提升大題。 距離目標 GKV 78 還差約 26 分。 語基(0/4)未滿,建議每天刷1–2道高考語用/病句真題,總結錯因。 默寫(5/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |
| 致知3班 | 38 | 76 | 63 | 115.2 | 4 | 5 | 高考向度得分不錯,已在正確訓練軌道上。 距離目標 GKV 78 還差約 15 分。 默寫(5/10)未滿,建議按篇滾動默寫並自查錯字、漏字。 大作文約 31/40,屬可以提升區,建議精改1–2篇真題作文,拆解高分結構。 |